本篇的相关参考代码地址:https://github.com/livoras/simple-virtual-dom
自己的代码整理:https://github.com/wxx2258/front-end-knowledge/tree/master/js%E6%A1%86%E6%9E%B6/react.js目录:
- 个人在大一下学期开始接触和学习前端,在工作室师兄师姐的帮助下,在前端的道路上不断前行,到现在,自己已经自学了一年半的前端了。从jq的使用到对js的基础学习,再到学习backbone,react.js的使用,对于react.js的使用和学习,从一开始的新奇, 疑问,到惊叹。
- 随着时间的推进,自己使用框架的同时,也开始发现,使用一个框架不能单单的去用就算了,对其中的原理和思想的学习也是很重要的。
- react.js 的核心部分大概为:
- 虚拟dom对象 (Vitual Dom)
- 虚拟dom差异化算法 (diff algorithm)
- 单向数据流渲染(Data Flow)
- 组件生命周期
- 事件处理
- 本篇章主要讲述 虚拟dom对象 和 dom diff算法 。
对前端应用状态管理的思考
假如现在你需要写一个像下面一样的表格的应用程序,这个表格可以根据不同的字段进行升序或者降序的展示。
这个应用程序看起来很简单,你可以想出好几种不同的方式来写。最容易想到的可能是,在你的 JavaScript 代码里面存储这样的数据:1
2
3var sortKey = "new" // 排序的字段,新增(new)、取消(cancel)、净关注(gain)、累积(cumulate)人数
var sortType = 1 // 升序还是逆序
var data = [{...}, {...}, {..}, ..] // 表格数据
用三个字段分别存储当前排序的字段、排序方向、还有表格数据;
–> 然后给表格头部加点击事件:当用户点击特定的字段的时候,根据上面几个字段存储的内容来对内容进行排序,
–> 然后用 JS 或者 jQuery 操作DOM,更新页面的排序状态(表头的那几个箭头表示当前排序状态,也需要更新)和表格内容。
这样做会导致的后果就是:随着应用程序越来越负载,需要在js里面维护的代码也越来越多,需要监听事件和在事件回调更新dom操作越来越多,应用程序越来越难以维护。
一旦视图中的状态有所改变,那就需要dom操作,在MVC框架中,我们还是无法减少维护的状态,需要操作的dom操作还是一样多,只是换了个地方而已。在MVVM中,就是在状态发生改变后,使用模板引擎重新构造整棵树,但这样会很慢,性价比太低。所以我们需要的是状态改变对应局部的更新。
React.js中,其实Virtual DOm 就是维护状态,更新试图,而且策略的避免了整棵DOM树变更。
Virtual DOM算法
DOM是很慢的。如果我们把一个简单的div元素的属性都打印出来,你会看到:
可以看出,真正的DOM元素非常庞大,这是因为标准就是这么设计的。而且操作他们的时候要小心,一旦经常触碰重排,性能就将受到影响。
相对于DOM对象,原声的javascript对象处理起来更快,也更简单,属性信息可以通过javascript对象表现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18var element = {
tagName: 'ul', // 节点标签名
props: { // DOM的属性,用一个对象存储键值对
id: 'list'
},
children: [ // 该节点的子节点
{tagName: 'li', props: {class: 'item'}, children: ["Item 1"]},
{tagName: 'li', props: {class: 'item'}, children: ["Item 2"]},
{tagName: 'li', props: {class: 'item'}, children: ["Item 3"]},
]
}
上面对应的HTML写法是:
<ul id='list'>
<li class='item'>Item 1</li>
<li class='item'>Item 2</li>
<li class='item'>Item 3</li>
</ul>
既然DOM树的信息都可以用javascript对象来表示,那就可以用javascript对象表示的树结构来构建一棵真正的DOM树。而Virtual DOM 算法这是实现这个事情的。
Virtual DOM 算法,包括几个步骤:
- 用javascript对象结构表示DOM 树的结构,然后用这个树构造一个真正的DOM 树,插到文档
- 当状态变更的时候,重新构造一颗新的对象树,然后用新的树和旧的树进行比较,记录两棵树的差异
- 把上面一步记录的差异应用到原先构建真正的DOM树上,试图就更新了。
Virtual DOM 本质上就是js和DOM之间做了一个缓存。
算法实现
步骤一:用JS对象模拟DOM树。
- 用javascript来表示一个DOM节点,只需要记录它的节点类型,属性,还有子节点:
1 | //注意:之后的代码使用了ES6 一些语法。有不明之处请读者自行了解。 |
例如上面的DOM结构就可以简单的表示:
1 | var el = require('./element') |
- 现在的ul只是一个javascript对象表示的DOM结构,页面上并没有这个结构,我们可以根据这个ul 构建真正的
- :
1 | Element.prototype.render = function () { |
render 方法可以根据tagName构建一个真正的Dom节点,然后设置这个节点的属性,最后递归吧自己的子节点也构建起来。只需要:
1 | var ulRoot = ul.render() |
步骤二:比较两棵虚拟DOM树的差异
差异比较的优化
正如很多人斗志到,比较两棵DOM 数的差异是 Virtual DOM 算法最核心的地方,也就是 Dom diff算法。
- 传统的diff算法,通过循环递归对节点进行依次对比,算法复杂度达到O(n^3),其中 n 是树中节点的总数。稍微对算法的有一定学习的人都知道,O(n^3)这样的算法复杂度效率究竟低下。
- React diff,React通过制定大胆的策略,将O(n^3) 复杂度的问题转换成 O(n) 复杂度的问题。
diff策略
- Web UI 中 DOM 节点跨层级的移动操作特别少,可以忽略不计。
- 拥有相同类的两个组件将会生成相似的树形结构,拥有不同类的两个组件将会生成不同的树形结构。
- 对于同一层级的一组子节点,它们可以通过唯一 id 进行区分。
tree diff
基于策略一,React 对树的算法进行了简洁明了的优化,即对树进行分层比较,两棵树只会对同一层次的节点进行比较。
既然 DOM 节点跨层级的移动操作少到可以忽略不计,针对这一现象,React 通过 updateDepth 对 Virtual DOM 树进行层级控制,只会对相同颜色方框内的 DOM 节点进行比较,即同一个父节点下的所有子节点。当发现节点已经不存在,则该节点及其子节点会被完全删除掉,不会用于进一步的比较。这样只需要对树进行一次遍历,便能完成整个 DOM 树的比较。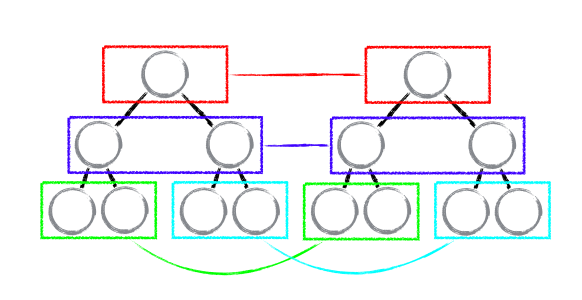
如果出现了 DOM 节点跨层级的移动操作,React diff 会有怎样的表现呢?
由于React只考虑同层级节点的位置变换,而对于不同级层,只有创建和删除。
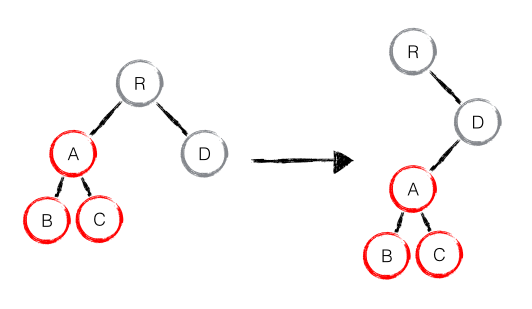
component diff
React 是基于组件构建应用的,对于组件间的比较所采取的策略也是简洁高效。
如果是同一类型的组件,按照原策略继续比较 virtual DOM tree。
如果不是,则将该组件判断为 dirty component,从而替换整个组件下的所有子节点。
对于同一类型的组件,有可能其 Virtual DOM 没有任何变化,如果能够确切的知道这点那可以节省大量的 diff 运算时间,因此 React 允许用户通过 shouldComponentUpdate() 来判断该组件是否需要进行 diff。
如下图,当 component D 改变为 component G 时,即使这两个 component 结构相似,一旦 React 判断 D 和 G 是不同类型的组件,就不会比较二者的结构,而是直接删除 component D,重新创建 component G 以及其子节点。虽然当两个 component 是不同类型但结构相似时,React diff 会影响性能,但正如 React 官方博客所言:不同类型的 component 是很少存在相似 DOM tree 的机会,因此这种极端因素很难在实现开发过程中造成重大影响的。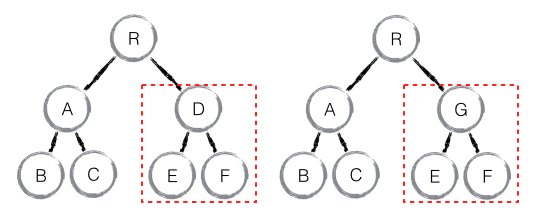
element diff
节点操作
当节点处于同一层级时,React diff 提供了三种节点操作,分别为:INSERT_MARKUP(插入)、MOVE_EXISTING(移动)和 REMOVE_NODE(删除)。
- INSERT_MARKUP,新的 component 类型不在老集合里, 即是全新的节点,需要对新节点执行插入操作。
- MOVE_EXISTING,在老集合有新 component 类型,且 element 是可更新的类型,generateComponentChildren 已调用 receiveComponent,这种情况下 prevChild=nextChild,就需要做移动操作,可以复用以前的 DOM 节点。
- REMOVE_NODE,老 component 类型,在新集合里也有,但对应的 element 不同则不能直接复用和更新,需要执行删除操作,或者老 component 不在新集合里的,也需要执行删除操作。
1 | function enqueueInsertMarkup(parentInst, markup, toIndex) { |
优化情景
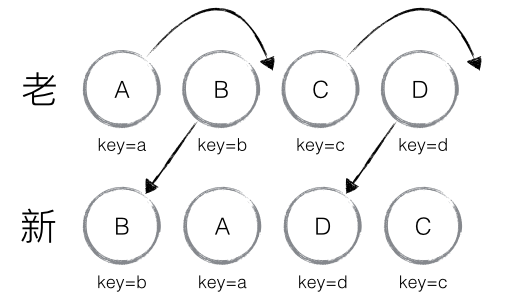
如下图,老集合中包含节点:A、B、C、D,更新后的新集合中包含节点:B、A、D、C,
此时新老集合进行 diff 差异化对比,发现 B != A,则创建并插入 B 至新集合,删除老集合 A;
以此类推,创建并插入 A、D 和 C,删除 B、C 和 D。
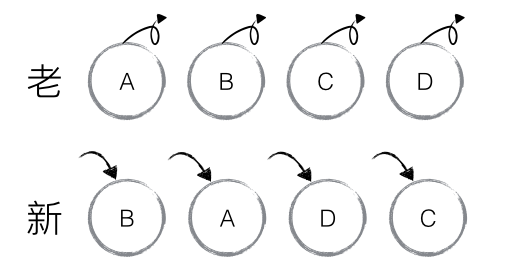
React发现这类操作繁琐冗余,因为这些都是些相同的节点,只是因为位置发生变化,导致需要进行繁杂低效的删除,创建操作。
针对这一现象,React提出优化策略:允许开发者对同一层级子节点,添加唯一key进行区分。
新老集合所包含的节点,如下图所示,新老集合进行 diff 差异化对比,
通过 key 发现新老集合中的节点都是相同的节点,因此无需进行节点删除和创建,
只需要将老集合中节点的位置进行移动,更新为新集合中节点的位置,
此时 React 给出的 diff 结果为:B、D 不做任何操作,A、C 进行移动操作,即可。
优化分析
- 首先对新集合的节点进行循环遍历,for (name in nextChildren),通过唯一 key 可以判断新老集合中是否存在相同的节点,
- if (prevChild === nextChild),
- 如果存在相同节点,则进行移动操作,
- 但在移动前需要将当前节点在老集合中的位置与 在新集合中的位置lastIndex 进行比较,
- if (child._mountIndex < lastIndex),则进行节点移动操作,否则不执行该操作。
- 更新 lastIndex = Math.max(prevChild._mountIndex, lastIndex)
- 这是一种顺序优化手段,lastIndex 一直在更新,表示访问过的节点在老集合中最右的位置(即最大的位置),
- 如果新集合中当前访问的节点比 lastIndex大, 说明当前访问节点在老集合中就比上一个节点位置靠后,则该节点不会影响其他节点的位置,因此不用添加到差异队列中,即不执行移动操作,只有当访问的节点比 lastIndex 小时,才需要进行移动操作。
- 如果存在相同节点,则进行移动操作,
步骤2.1:深度优先遍历,记录差异
在实际的代码中,会对新旧两棵树进行一个深度优先的遍历(学过数据结构或者离散数学的应该都熟知深度优先的遍历,如果你还不知道深度优先的遍历,请自己学习这一算法。),这样每个节点都会有一个唯一的标记:
1 | // diff 函数,对比两棵树 |
例如,上面的div和新的div有差异,当前的标记是0,那么:
patches[0] = [{difference}, {difference}, …] // 用数组存储新旧节点的不同
同理p是patches[1],ul是patches[3],类推。
步骤2.2:差异类型
上面说的节点的差异指的是什么呢?对 DOM 操作可能会:
- 替换掉原来的节点,例如把上面的div换成了section
- 移动、删除、新增子节点,例如上面div的子节点,把p和ul顺序互换
- 修改了节点的属性
- 对于文本节点,文本内容可能会改变。例如修改上面的文本节点2内容为Virtual DOM2 。
所以我们定义了几种差异类型:
1 | var REPLACE = 0 |
- 对于节点替换,很简单。判断新旧节点的tagName和是不是一样的,如果不一样的说明需要替换掉。如div换成section,就记录下:
1 | patches[0] = [{ |
- 如果给div新增了属性id为container,就记录下:
1 | patches[0] = [{ |
- 如果是文本节点,如上面的文本节点2,就记录下:
1 | patches[2] = [{ |
那如果把我div的子节点重新排序呢?
例如p, ul, div的顺序换成了div, p,ul。
这个该怎么对比?如果按照同层级进行顺序对比的话,它们都会被替换掉。如p和div的tagName不同,p会被div所替代。最终,三个节点都会被替换,这样DOM开销就非常大。而实际上是不需要替换节点,而只需要经过节点移动就可以达到,我们只需知道怎么进行移动。
这种情况我们在前面element diff已经有所讨论,不加赘述。
步骤2.3:把差异应用到真正的DOM树上
因为步骤一所构建的 JavaScript 对象树和render出来真正的DOM树的信息、结构是一样的。所以我们可以对那棵DOM树也进行深度优先的遍历,遍历的时候从步骤二生成的patches对象中找出当前遍历的节点差异,然后进行 DOM 操作。
1 | function patch (node, patches) { |
applyPatches,根据不同类型的差异对当前节点进行 DOM 操作:
1 | function applyPatches (node, currentPatches) { |
结语
Virtual DOM 算法主要是实现上面步骤的三个函数:element,diff,patch。然后就可以实际的进行使用:
1 | // 1. 构建虚拟DOM |
当然这是非常粗糙的实践,实际中还需要处理事件监听等;生成虚拟 DOM 的时候也可以加入 JSX 语法。这些事情都做了的话,就可以构造一个简单的ReactJS了。
Refernces
深度剖析:如何实现一个 Virtual DOM 算法(作者:戴嘉华)
React 源码剖析系列 - 不可思议的 react diff (作者:twobin)